Harnessing Weak Supervision to Isolate Sign Language Communicators in Crowded News Videos
This post is part of a new foundation that we are trying to create – Longtail AI Foundation, that works towards increasing accessibility for the hearing impaired. It describes our first steps towards creating a large-scale dataset – isl-500 for training bi-directional translation models between English and Indian Sign Language (ISL).
Introduction
|
I believe that we can solve continuous sign language translation convincingly, if we have access to truly large-scale datasets. Compare with Audio Transcription, by considering Table 6. from Whisper, the state-of-the-art audio transcription system. Their lowest word-error rate (WER) of 9.9, requires 680K hours of noisy transcribed audio data. It is unlikely that such a dataset will ever exist for Sign Language Translation; the footprint of the hearing-impaired on the Internet is far too small.
This is not a problem, since the table also shows that with 6.8K hours, the model achieves a word error rate of 19.6. This is pretty impressive considering that OpenAI evaluated their models on datasets that, for one weren’t seen during training but secondly, and more importantly, came from a variety of sources and were made by entirely different groups.
This is in stark constrast with current SL research where most papers report numbers on the validation sets of the same dataset used in training (commonly used datasets are CSL-Daily for Chinese SL and Phoenix-2014T for German SL. These datasets are on the order of 100 hours). While over years, the numbers improve, they themselves aren’t indicative of how these SL Translation systems perform in-the-wild and whether they bring meaningful impact to the lives of the hearing-impaired.
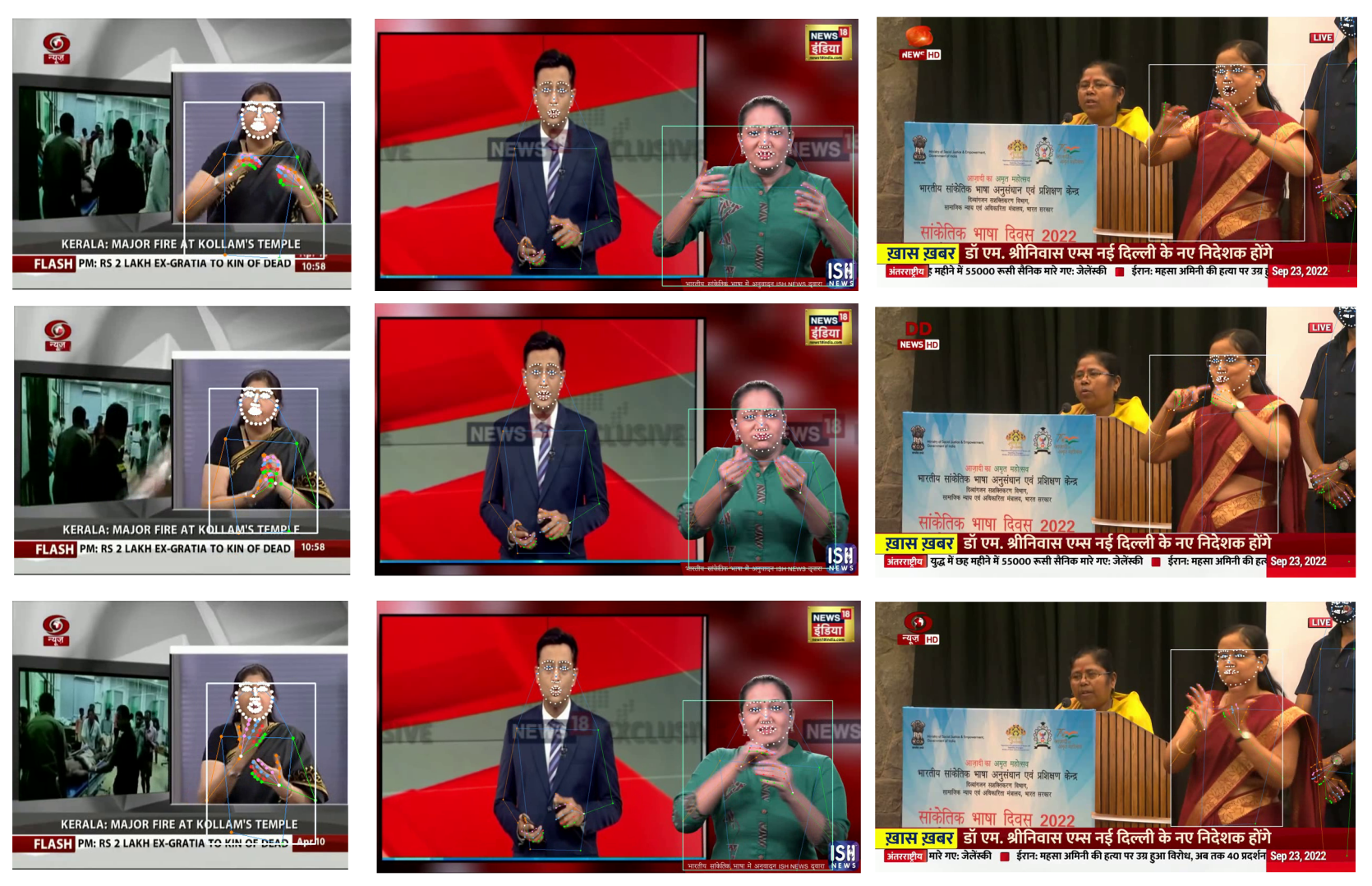
All this is to say, that we need to build a 5000 hour scale dataset for Sign Language Translation and we are good to go. But where can we find this data? Luckily news broadcasters often include special news segments for the hearing-impaired. In these segments, a hand-signer gesticulates words while simultaneously, an anchor reads out the news. By detecting the hand-signer and pairing their gestures with audio transcriptions, we can start making progress on this problem. The steps to do detect hand-signers are described below.

|
We first run a human pose estimation model DWPose on news videos that we collected from YouTube. We design heuristics to label to pose sequences. These heuristics are described in detail later in this post. Some of these heuristics may abstain from labelling while others may not be applicable at test time. We use Snorkel to aggregate these heuristics and assign probabilistic labels on an unlabelled training set. Internally, Snorkel weighs agreement/disagreement between heuristics on the entire unlabelled training set to assign probabilistic labels. We use these probabilistic labels to train a hand-signer classifier on pose sequences. Since Snorkel is only applicable during training time, it’s necessary to train the classifier so that we can use it later to detect hand-signers.
Snorkel: Making sense of Weak Labels
Let me be up front. I don’t know how Snorkel works. But let me use this space to pass on some intuition, regarding why such a system may improve the quality of heuristic labels. Let’s say we have 5 heuristics A, B, C, D and E. A, B and C agree on everything but are random i.e. they label by flipping a coin. D and E, on the other hand, are pretty accurate.
Consider using majority vote to combine these heuristics. It’s evident that since A, B and C always vote the same way, they represent the majority. All the valuable information from heuristics D and E is lost in this exercise.
My guess is that Snorkel improves on majority vote by detecting correlations between heuristics and avoids double, or in this case, triple counting certain heuristics. Thus, its probabilistic labels are more reliable than the heuristics themselves.
Heuristics for classifying Hand-Signers
Here I describe the heuristics I developed for classifying pose sequences.
num tracks: This heuristic counts the number of humans simultaneously tracked in a sequence. If there are many people tracked, it’s unlikely that any one of them is a signer. This is a really coarse heuristic, but the table below shows that it is better than random (which will have an error rate of 0.5 for this binary classification problem).video path: This heuristic assigns labels based on the data source. For example, if the sequence came from a Sign Language dictionary, we can be sure that the tracked person is indeed a hand-signer. This heuristic has 0 error rate but has poor coverage as well. It highlights a common tradeoff in designing heuristics: it is hard to design heuristics that label all samples in the dataset with low error rate.legs visible: While going through News Videos, I found that most hand-signers are either sitting, or are too close to the camera, so that their legs are not visible. Using pose estimation confidence scores, we can check this and assign a label.only one person: This is similar to thenum trackheuristic. If there is only one person tracked, it’s likely that the person is a hand-signer.bounding box: This heuristic checks if the bounding box of a person is too small compared to video dimensions. If so, it’s unlikely that the person is a hand-signer.movement: This heuristic measure how much a person is moving their hands. If it is above a certain threshold, they are probably a hand-signer. This heuristic is pretty good, already achieving pretty low error rate and 100% coverage.chest level: This heuristic simply checks whether a person’s hands cross their chest. If so, they maybe a hand-signer.
| Heuristic | Error Rate (dev) ↓ | Error Rate (test) ↓ | Coverage (dev) ↑ | Coverage (test) ↑ |
|---|---|---|---|---|
| num tracks | 0.28 | 0.27 | 1.00 | 1.00 |
| video path | 0.00 | 0.00 | 0.02 | 0.02 |
| legs visible | 0.19 | 0.15 | 1.00 | 1.00 |
| only one person | 0.05 | 0.03 | 0.35 | 0.37 |
| bounding box | 0.23 | 0.21 | 1.00 | 1.00 |
| movement | 0.05 | 0.08 | 1.00 | 1.00 |
| chest level | 0.15 | 0.16 | 1.00 | 1.00 |
Table 1: Labelling Functions: Error Rate (1 − Accuracy) and Coverage (the fraction of data points they don’t abstain from labelling) of different labelling functions. Note that our dev and test sets are class balanced i.e. they have equal number of hand-signers and non-hand-signers. The dev set was used to tune the thresholds in the heuristics.
Evaluation
I compared our classifier trained on Snorkel’s probabilistic labels against few reasonable baselines. The simplest one is a majority vote, where among all the non-abstaining heuristics, we choose the majority vote. From the table, we can confirm our intuition that majority vote is not good. In fact, it’s worse than our best heuristic (movement).
To control for the effect of Snorkel, we also trained the classifier on labels from the movement heuristic. It is not surprising that this doesn’t meaningfully impact the error rate. In fact, had it done so, I’d be more likely to attribute it to a bug in my code than to anything else.
Training on Snorkel’s probabilistic labels produces the best error rate. They are half of our best-performing heuristic (both on the dev and test set, incidentally).
| Method | Error Rate (dev) ↓ | Error Rate (test) ↓ |
|---|---|---|
| majority vote | 0.13 | 0.12 |
| movement heuristic | 0.05 | 0.08 |
| movement heuristic + classifier | 0.04 | 0.08 |
| ours | 0.02 | 0.04 |
Table 2: Error rates: We compare our final classifier against reasonable baselines (the best performing heuristic, a classifier trained on the best performing heuristic, and a majority vote among all heuristics). Pooling heuristic labels using Snorkel and training a classifier slashes the error rate by at least 50% on both our dev and test set.
Final Thoughts
I should point out that Snorkel is not a magic wand. The heuristics that one uses should be pretty good already and should broadly cover the dataset. Also, detecting hand-signers is quite a simple computer-vision problem, in the era of GPT-4o. That being said, it is pretty exciting that it works at all and should make data acquisition cheaper in a lot of use cases.
Our code is available on GitHub. We have used it to clean ~ 500 hours of news videos (ISL) along with transcripts. If anyone has any use for this this dataset/code, please reach out to us. Any thoughts/suggestions will be appreciated.